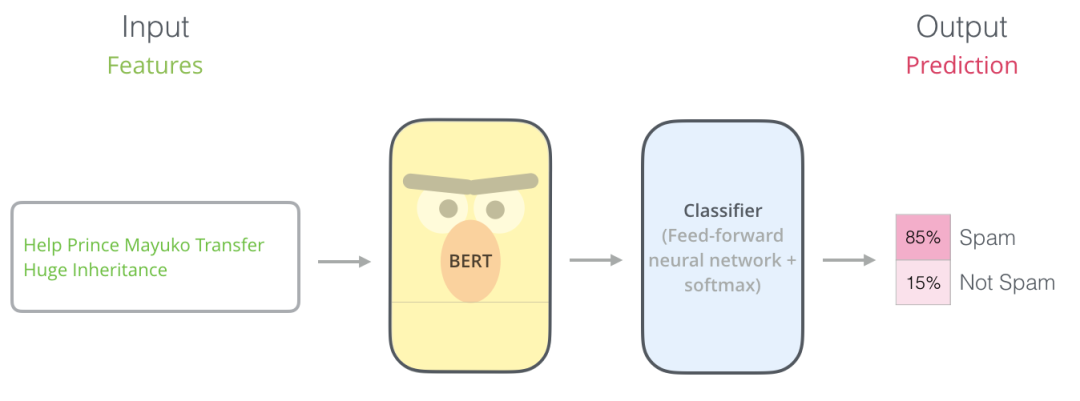
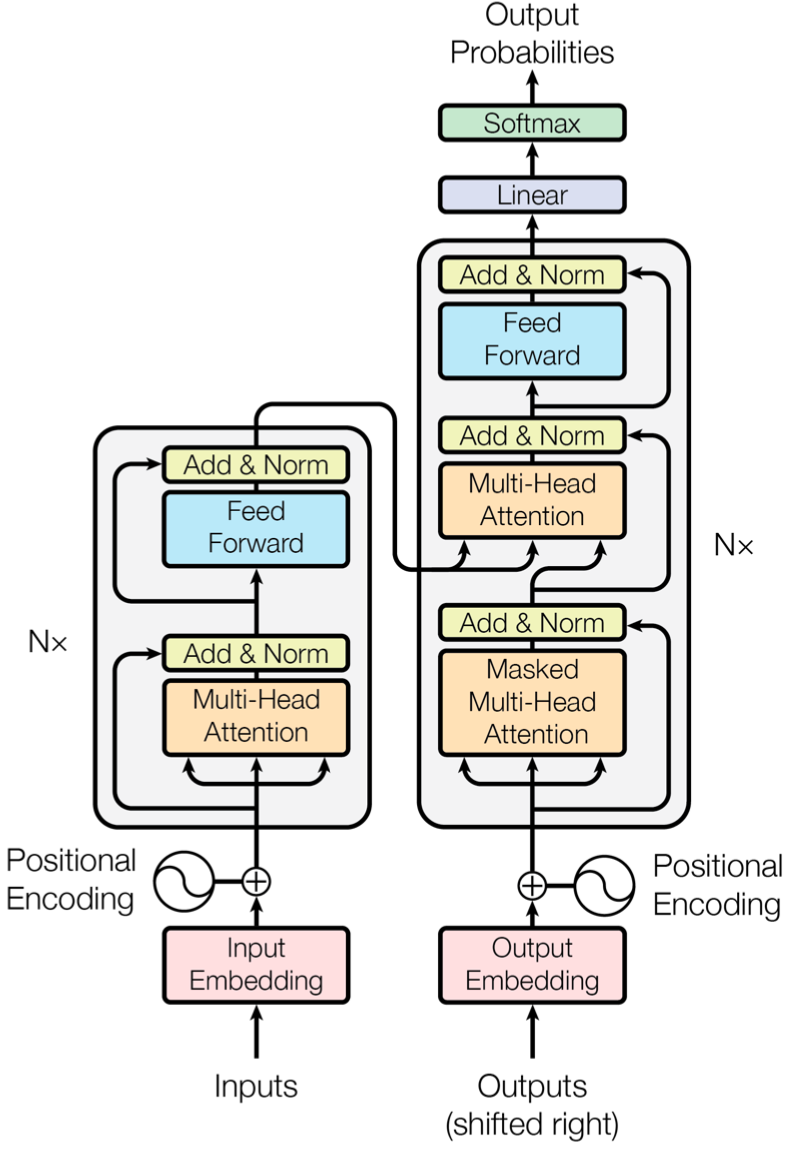
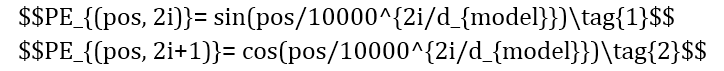01迁移学习 Transformer是谷歌于2017年年底在论文《Attention is all you need》[2]中提出的一种序列到序列(Seq2seq)模型,它主要由编码器(Encoder)和解码器(Decoder)两部分组成,详见图3。介绍Transformer模型最好例子就是它在机器翻译中的应用。在英文翻译成中文过程中,编码器负责阅读与学习输入的英文文本,通过捕捉载体所包含信息学会一定的语言概念,这被称为是上下文(Context)。上下文信息本质是语义在向量空间的一种映射,即语义的数学化表达,一个著名例子就是:国王-男性+女性=女王。之后,编码器将所学内容以隐藏层(Hidden Layer)形式传递给解码器,解码器再利用这些知识进行文本翻译工作。具体来说,在生成中文文本过程中,解码器会对当前中文单词根据上下文信息来预测下一个中文单词,之后再根据下一个词预测下一个词的下一个词,循环往复,直至生成完整句子,这种做法也体现了序列模型的特性。由于BERT目标是生成用于语言表示的预训练模型,因此只需要编码器部分即可。所学到上下文信息在BERT中以768维度向量存储。
图3. Transformer模型结构
02位置嵌入
在序列模型中,词在句中位置对语料学习尤为重要。在训练文本时,长短时记忆网络(Long Short Term Memory Network, LSTM)通过一定的顺序读取文本:从左向右或是从右向左,以此来得到词在文中的位置信息,这样的模型称为单向模型。 与单向模型不同的是,在词向量(Word Embedding)进入编码器之前,Transformer模型使用位置编码(Positional Encoding)来提供语序信息。这种设计通过为词向量加入独一无二的纹理信息来表征词在句中的位置,纹理信息则通过sin函数与cos函数的线性变换(公式1-2)生成。因此,编码器可以一次读取整个文本序列,这样的语境化特性使Transformer可以基于词的所有周围环境来学习上下文,并且可以接收更庞大的数据量。